
一、背景
1. 什么是缓存无底洞问题:
Facebook的工作人员反应2010年已达到3000个memcached节点,储存数千G的缓存。
他们发现一个问题--memcached的连接效率下降了,于是添加memcached节点,添加完之后,并没有好转。称为“无底洞”现象
2. 缓存无底洞产生的原因:
键值数据库或者缓存系统,由于通常采用hash函数将key映射到对应的实例,造成key的分布与业务无关,但是由于数据量、访问量的需求,需要使用分布式后(无论是客户端一致性哈性、redis-cluster、codis),批量操作比如批量获取多个key(例如redis的mget操作),通常需要从不同实例获取key值,相比于单机批量操作只涉及到一次网络操作,分布式批量操作会涉及到多次网络io。
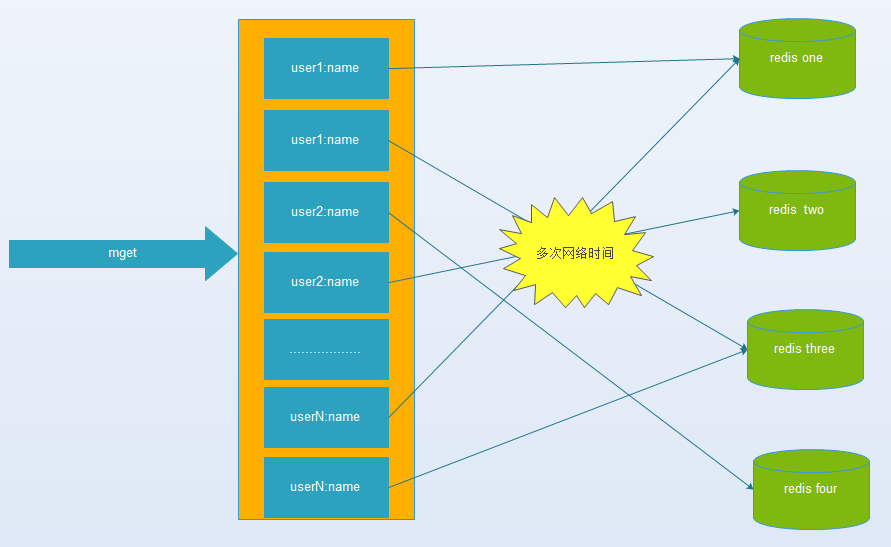
3. 无底洞问题带来的危害:
(1) 客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着实例的增多,耗时会不断增大。
(2) 服务端网络连接次数变多,对实例的性能也有一定影响。
4. 结论:
用一句通俗的话总结:更多的机器不代表更多的性能,所谓“无底洞”就是说投入越多不一定产出越多。
分布式又是不可以避免的,因为我们的网站访问量和数据量越来越大,一个实例根本坑不住,所以如何高效的在分布式缓存和存储批量获取数据是一个难点。
二、哈希存储与顺序存储
在分布式存储产品中,哈希存储与顺序存储是两种重要的数据存储和分布方式,这两种方式不同也直接决定了批量获取数据的不同,所以这里需要对这两种数据的分布式方式进行简要说明:
1. hash分布:
hash分布应用于大部分key-value系统中,例如memcache, redis-cluster, twemproxy,即使像mysql在分库分表时候,也经常会用user%100这样的方式。
hash分布的主要作用是将key均匀的分布到各个机器,所以它的一个特点就是数据分散度较高,实现方式通常是hash(key)得到的整数再和分布式节点的某台机器做映射,以redis-cluster为例子:
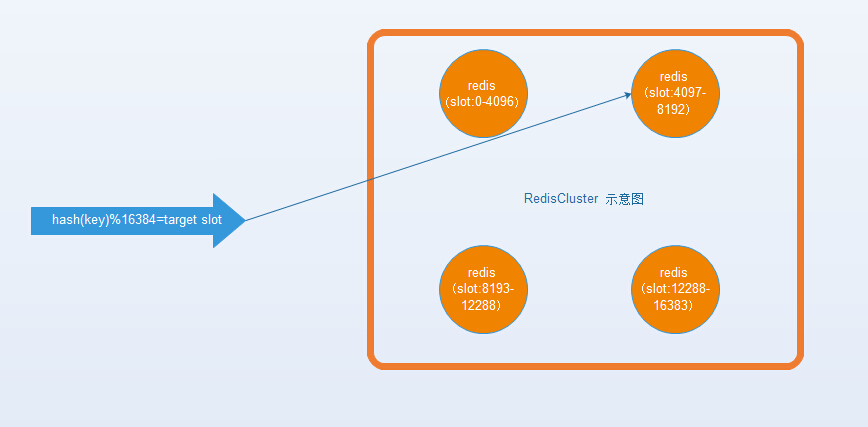
问题:和业务没什么关系,不支持范围查询。
2. 顺序分布

3. 两种分布方式的比较:
| 分布方式 | 特点 | 典型产品 |
| 哈希分布 | 1. 数据分散度高 2.键值分布与业务无关 3.无法顺序访问 4.支持批量操作 | 一致性哈希memcache redisCluster 其他缓存产品 |
| 顺序分布 | 1.数据分散度易倾斜 2.键值分布与业务相关 3.可以顺序访问 4.支持批量操作 | BigTable Hbase |
三、分布式缓存/存储四种Mget解决方案
1. IO的优化思路:
(1) 命令本身的效率:例如sql优化,命令优化
(2) 网络次数:减少通信次数
(3) 降低接入成本:长连/连接池,NIO等。
(4) IO访问合并:O(n)到O(1)过程:批量接口(mget),
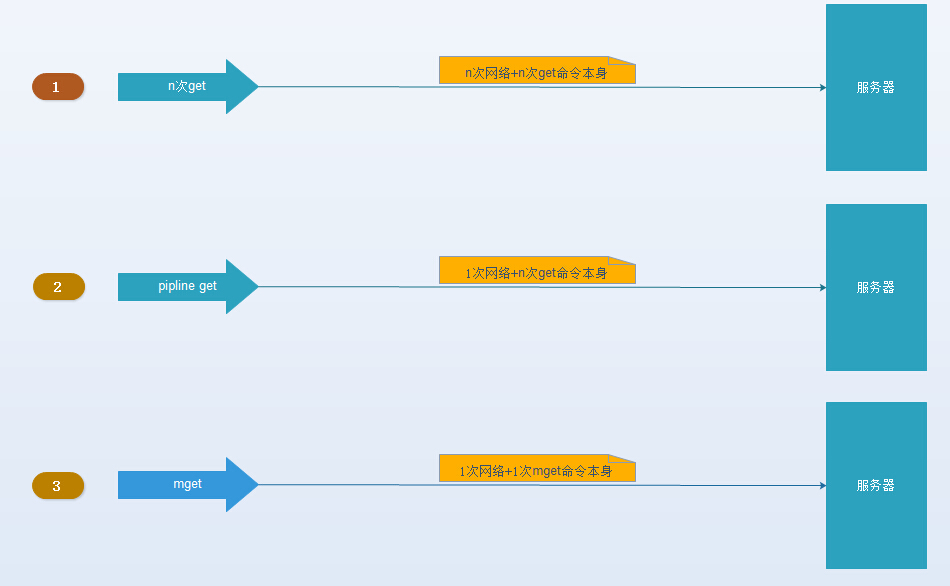
2. 如果只考虑减少网络次数的话,mget会有如下模型:
3. 四种解决方案:
(1).串行mget
将Mget操作(n个key)拆分为逐次执行N次get操作, 很明显这种操作时间复杂度较高,它的操作时间=n次网络时间+n次命令时间,网络次数是n,很显然这种方案不是最优的,但是足够简单。
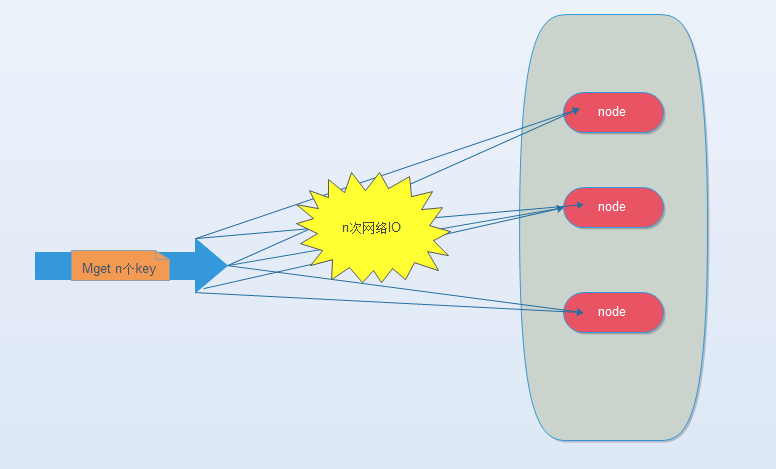
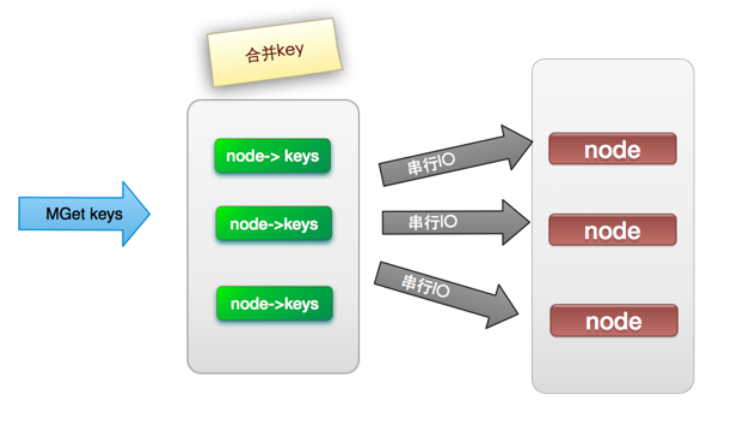
(2). 串行IO
将Mget操作(n个key),利用已知的hash函数算出key对应的节点,这样就可以得到一个这样的关系:Map<node, somekeys>,也就是每个节点对应的一些keys
它的操作时间=node次网络时间+n次命令时间,网络次数是node的个数,很明显这种方案比第一种要好很多,但是如果节点数足够多,还是有一定的性能问题。
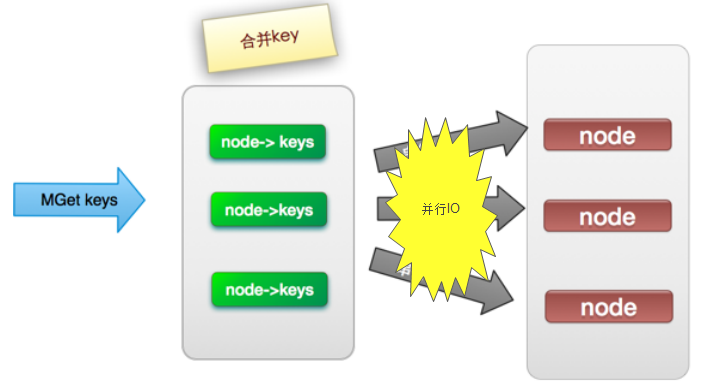
(3). 并行IO
此方案是将方案(2)中的最后一步,改为多线程执行,网络次数虽然还是nodes.size(),但网络时间变为o(1),但是这种方案会增加编程的复杂度。
它的操作时间=1次网络时间+n次命令时间
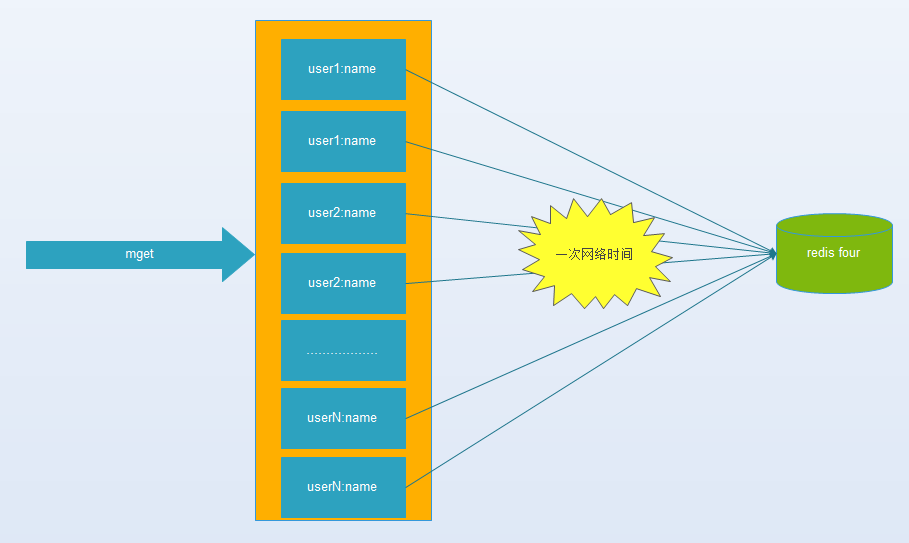
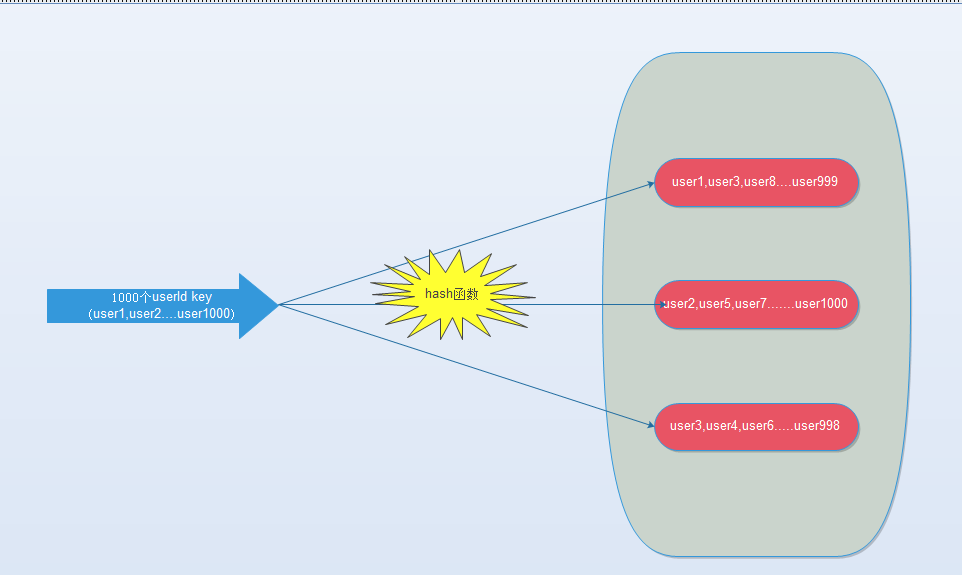
(4). hash-tag实现。
第二节提到过,由于hash函数会造成key随机分配到各个节点,那么有没有一种方法能够强制一些key到指定节点到指定的节点呢?
redis提供了这样的功能,叫做hash-tag。什么意思呢?假如我们现在使用的是redis-cluster(10个redis节点组成),我们现在有1000个k-v,那么按照hash函数(crc16)规则,这1000个key会被打散到10个节点上,那么时间复杂度还是上述(1)~(3)
那么我们能不能像使用单机redis一样,一次IO将所有的key取出来呢?hash-tag提供了这样的功能,如果将上述的key改为如下,也就是用大括号括起来相同的内容,那么这些key就会到指定的一个节点上。
例如:
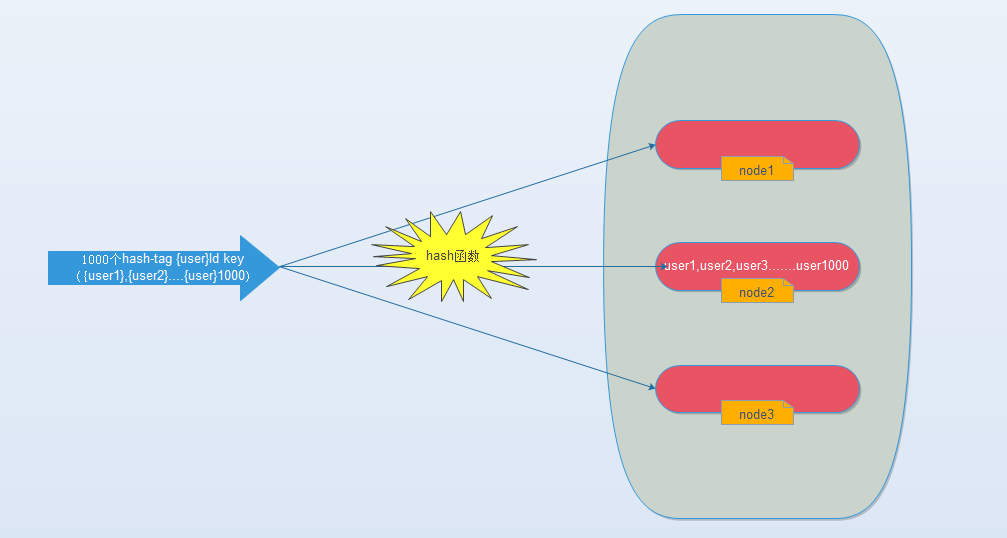
Java代码

- user1,user2,user3......user1000
- {user}1,{user}2,{user}3.......{user}1000
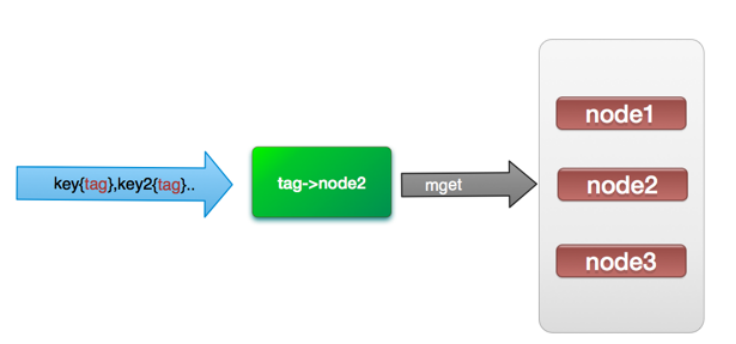
例如下图:它的操作时间=1次网络时间+n次命令时间
3. 四种批量操作解决方案对比:
| 方案 | 优点 | 缺点 | 网络IO |
| 串行mget | 1.编程简单 2.少量keys,性能满足要求 | 大量keys请求延迟严重 | o(keys) |
| 串行IO | 1.编程简单 2.少量节点,性能满足要求 | 大量node延迟严重 | o(nodes) |
| 并行IO | 1.利用并行特性 2.延迟取决于最慢的节点 | 1.编程复杂 2.超时定位较难 | o(max_slow(node)) |
| hash tags | 性能最高 | 1.tag-key业务维护成本较高 2.tag分布容易出现数据倾斜 | o(1) |
四、总结和建议
无底洞问题对资源和性能有一定影响,但是其实大部分系统不需要考虑这个问题,因为
1. 99%公司的数据和流量无法和facebook相比。
2. redis/memcache的分布式集群通常来讲是按照项目组做隔离的,以我们经验来看一般不会超过50对主从。
所以这里只是提供了一种优化的思路,开阔一下视野。
五、参考文献